
发布日期:2025-01-14 17:52 点击次数:152

IT之家 1 月 13 日讯息,据英伟达官方博客,英伟达书记推出一款名为 Nemotron-CC 的大型英文 AI 考研数据库萝莉 色情,认为包含 6.3 万亿个 Token,其中 1.9 万亿为合成数据。英伟达宣称该考研数据库不错匡助为学术界和企业界进一步股东大言语模子的考研过程。

现在,业界各种 AI 模子的具体性能主要取决于相应模子的考研数据。可是现存公开数据库在规模和质地上常常存在局限性,英伟达称 Nemotron-CC 的出现恰是为了惩办这一瓶颈,该考研数据库 6.3 万亿 Token 的规模内含大齐经过考证的高质地数据,堪称是“考研大型言语模子的理思素材”。
数据起头方面,Nemotron-CC 基于 Common Crawl 网站数据构建,并在经过严格的数据处理历程后,索求而成高质地子集 Nemotron-CC-HQ。
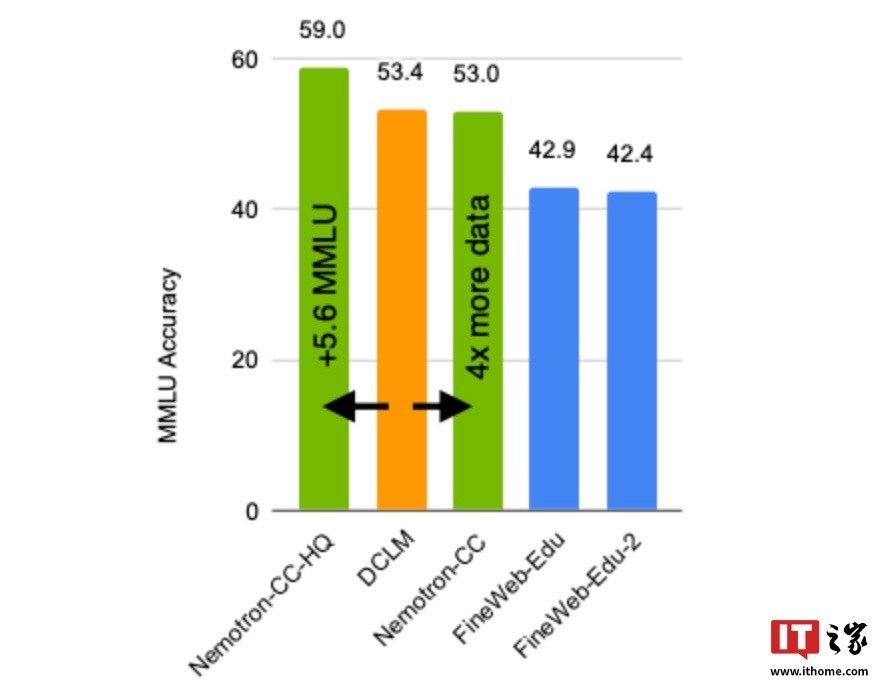
在性能方面,英伟达称与现在业界跳跃的公开英文考研数据库 DCLM(Deep Common Crawl Language Model)比较,使用 Nemotron-CC-HQ 考研的模子在 MMLU(Massive Multitask Language Understanding)基准测试中的分数提高了 5.6 分。
进一步测试潜入,使用 Nemotron-CC 考研的 80 亿参数模子在 MMLU 基准测试均分数进步 5 分,在 ARC-Challenge 基准测试中进步 3.1 分,并在 10 项不同任务的平均弘扬中提高 0.5 分,卓绝了基于 Llama 3 考研数据集缔造的 Llama 3.1 8B 模子。
英伟达官方暗示,Nemotron-CC 的缔造过程中使用了模子分类器、合成数据重述(Rephrasing)等时期,最大终了地保证了数据的高质地和各样性。同期他们还针对特定高质地数据裁汰了传统的启发式过滤器处理权重,从而进一步提高了数据库高质地 Token 的数目,并幸免对模子精准度形成毁伤。
IT之家珍惜到萝莉 色情,英伟达已将 Nemotron-CC 考研数据库已在 Common Crawl 网站上公开(点此拜访),英伟达称联系文档文献将在稍晚时刻于该公司的 GitHub 页中公布。